Afficher/cacher Sommaire
DocFetcher
![]()
Documentation dupliquée au format markdown (document original)
Liens
- DocFetcher → Documentation (fr)
- DocFetcher → Download
- DocFetcher → Screenshots
- DocFetcher → More
- DocFetcher → Wiki
Installation DocFetcher
Archlinux
yay -S docfetcher # ou yaourt -S, trizen -S, autre ...
Paramétrage utilisateur
Accès à DocFetcher via son API de script Python
Dans DocFetcher 1.1.20 et les versions ultérieures, DocFetcher prend en charge les scripts basés sur Python. Ceci peut être utilisé pour exécuter des recherches par programmation et récupérer les résultats. Pour un exemple de cette procédure, voir l’explication en haut du fichier search.py, qui se trouve dans le dossier du programme DocFetcher (archlinux : /usr/share/docfetcher/search.py).
Ce script envoie les arguments de ligne de commande donnés sous forme de requête à l’exécutable DocFetcher. Les résultats retournés par ce dernier sont imprimés sous forme de nom de fichier sur la sortie standard.
Pour un traitement plus avancé des résultats, appelez la fonction de recherche ci-dessous directement. En principe, vous pouvez également réutiliser le code dans la fonction de recherche pour scripter arbitrairement l’instance DocFetcher.
Par défaut, le support des scripts DocFetcher est désactivé pour des raisons de sécurité et doit être activée en définissant la variable “PythonApiEnabled” dans la fenêtre avancée (program-conf.txt) à “true”.
L’exécution de ce script nécessite Py4J (https://www.py4j.org/). DocFetcher déjà est livré avec une distribution Py4J, mais elle ne fonctionne que si le dossier py4j est dans le même dossier que ce script. Pour scripter DocFetcher à partir d’un emplacement différent, déplacez le dossier py4j, ou installez Py4J séparément (Archlinux : dossier py4j au même emplacement que le script search.py)
Notez que seule l’instance principale du programme DocFetcher prend en charge les scripts, et non l’instance DocFetcher “daemon”.
Activation du script ~/.config/docfetcher/program-conf.txt
PythonApiEnabled = true
Si l’instance DocFetcher autorise les scripts basés sur Py4J (search.py). Ce paramètre est désactivé par défaut pour des raisons de sécurité : En l’activant, DocFetcher exécutera un serveur TCP sur l’hôte local, qui est sujet à des exploits d’exécution de code local et (potentiels) à distance.
Le paramétrage utilisateur ~/.config/docfetcher/settings-conf.txt , on va désactiver “Touche raccourci globale”
HotkeyEnabled = false
Description
DocFetcher est une application Open Source pour la recherche de contenu local sur ordinateur: elle vous permet de faire des recherches dans le contenu des fichiers sur votre ordinateur.. L’application fonctionne sur Windows, Linux et Max OS X.
Elle est disponible sous licence Eclipse Public License.
Usage
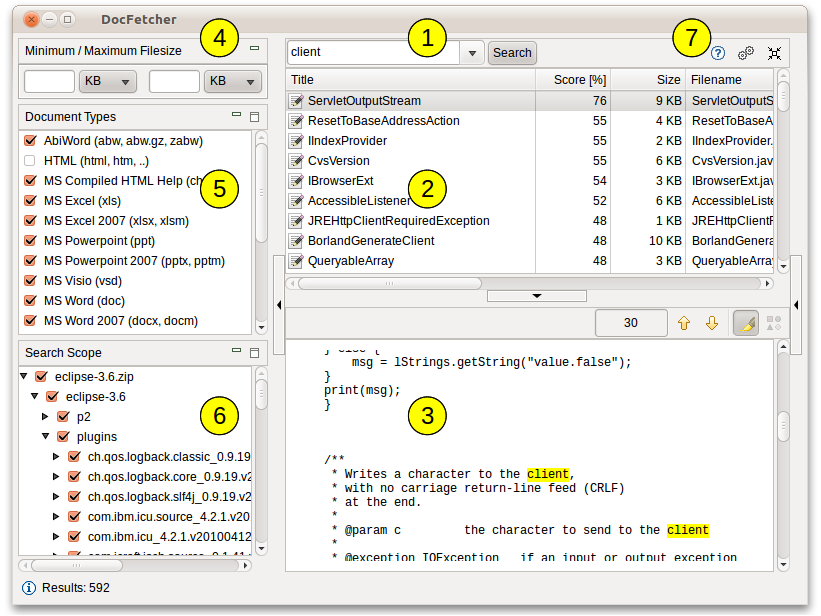
La capture d’écran ci dessous montre l’interface utilisateur principale. Les requêtes sont entrées dans le champ (1). Les résultats de la recherche apparaissent dans le panneau de résultat (2). Le panneau d’aperçu (3) montre seulement un aperçu du texte du fichier sélectionné dans le panneau résultat. Toutes les correspondances dans le fichiers sont surlignées en jaune.
Vous pouvez filtrer les résultats par taille minimale ou maximale (4), par type de fichier (5) et par emplacement (6). Les boutons (7) sont utilisés pour ouvrir le manuel, les menus de réglages et pour minimiser le programme dans la barre système.
DocFetcher a besoin que vous définissiez des index pour les dossiers dans lesquels vous voulez effectuer des recherches. Ce qu’est l’indexation et comment cela marche est expliqué plus en détails ci-dessous. En résumé, un index permet à DocFetcher de trouver très rapidement (on parle ici de millisecondes) quels fichiers contiennent un ensemble de mots, ainsi accélérant considérablement vos recherches. La capture d’écran qui suit montre la fenêtre de dialogue de DocFetcher pour créer de nouveaux index:
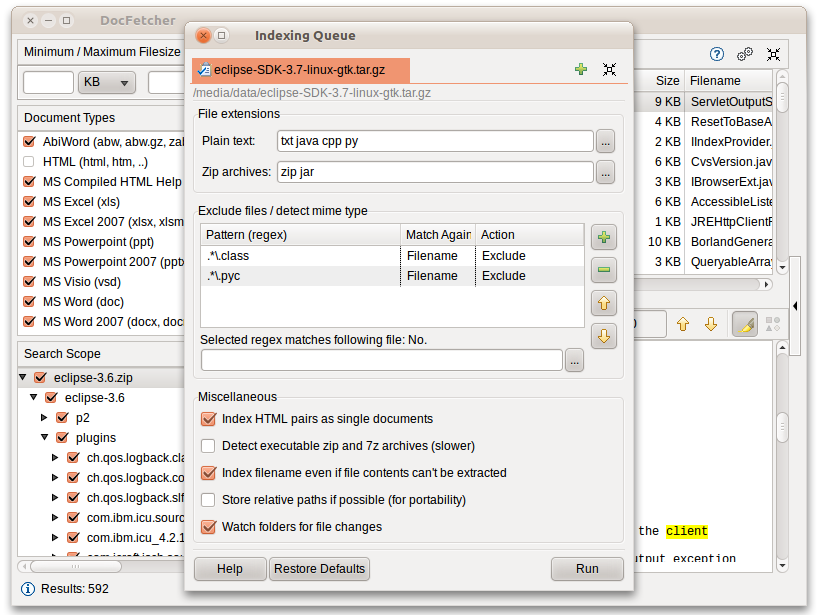
Cliquer sur le bouton “Démarrer” en bas à droite permet de commencer l’indexation. L’indexation peut durer un bon moment selon le nombre et la taille des fichiers qui doivent être indexés. En gros, il faut compter 200 fichiers par minute.
La création des index prend du temps mais elle n’a besoin d’être faite qu’une seule fois par dossier. De plus, mettre à jour un index après que son contenu ait changé est beaucoup plus rapide que de le créer — cela prend typiquement seulement quelques secondes.
Fonctions principales
- Une version portable: il y a une version portable de DocFetcher qui fonctionne sous Windows, Linux et Mac OS X. Son utilité est décrite avec plus de détails plus bas sur cette page.
- support 64-bit: les versions 32-bit et 64-bit des systèmes d’exploitations sont toutes deux supportées.
- support Unicode support: DocFetcher vient avec un support Unicode robuste pour tous les formats principaux, incluant Microsoft Office, OpenOffice.org, PDF, HTML, RTF et les fichiers texte bruts. La seule exception est CHM, pour lequel il n’y a pas encore de support Unicode.
- Support des archives: DocFetcher supporte les formats d’archive suivants: zip, 7z, rar, et la famille complète des tar.*. Les extensions de fichiers peuvent être configurées afin de vous permettre d’ajouter plus de formats d’archives basés sur le format zip si nécessaire. De plus, DocFetcher gère un nombre illimité d’archives imbriquées (ex: une archive zip qui contient une archive 7z qui contient une archive rar… etc).
- Recherche dans les fichiers de code source: Les extensions que DocFetcher reconnait comme fichiers texte peuvent être configurées, de manière à ce que vous puissiez utiliser DocFetcher pour chercher n’importe quel type de fichier code source et de fichier basés sur du texte. (Ceci marche assez bien en combinaison avec la configuration des extensions zip par exemple pour chercher dans des fichiers code source à l’intérieur de fichiers Jar)
- Fichiers Outlook PST: DocFetcher permet de chercher les messages Outlook, que Microsoft Outlook stocke typiquement dans des fichiers PST.
- Détection de paires HTML : Par défaut, DocFetcher détecte les paires de fichiers HTML (ex: un fichier est nommé “toto.html” et un dossier “toto_files”), et les traite comme un document unique. Cette fonction peut paraître inutile de prime abord, mais cela augmente considérablement la qualité des résultats de recherche pour les fichiers HTML, dans la mesure ou tout le “bazar” dans le dossier HTML disparaît des résultats.
-
exclusion de fichier à indexer basée des expressions régulières (Regex): vous pouvez utiliser des expression régulières pour exclure des fichiers de l’indexation. Par exemple, pour exclure des fichiers Microsoft Excel, vous pouvez utiliser une expression régulière comme ceci:
.*\.xls
Autre exemple, exclure les dossiers “.svn” de l’indexation ?
Dans la boîte de dialogue d’indexation, utilisez ce motif d’exclusion regex :.*/\.svn/.*
Notez l’utilisation de barres obliques vers l’avant pour correspondre aux séparateurs de chemins (même sous Windows !), et l’échappement du “. “ avec une barre oblique vers l’arrière “".En outre, “Match Against” doit être réglé sur “Absolute path”. - Détection des types Mime: Vous pouvez utiliser des expressions régulières pour activer la détection du type mime pour certains fichiers, ce qui veut dire que DocFetcher essaiera de détecter le vrai type de fichier en pas seulement en se basant sur le nom mais aussi en regardant à l’intérieur. Ceci est utile pour les fichiers qui ont une mauvaise extension.
- Une syntaxe puissante pour les requêtes: en plus de constructions basiques comme et, ou et pas (OR, AND et NOT), DocFetcher supporte aussi entre autres: les caractères de remplacement, les recherches de phrase, les recherches floues (“trouver des mots similaires à…”), la recherche de proximité (“ces deux mots devraient être au plus à 10 mots d’intervalle l’un de l’autre”), “boosting” (“augmenter le score des documents qui contiennent…”)
Formats de documents supportés
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 et versions plus récentes (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- HTML (html, xhtml, …)
- Texte brut (configurable)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Comparaison avec d’autres de programme de recherche de fichiers locaux
Comparaison avec d’autres programmes de recherche de fichiers locaux
voici où DocFetcher se démarque:
- Sans m…: Nous travaillons dur pour conserver l’interface de DocFetcher simple et sans bazar. Pas de publicité ou de “Voudriez-vous vous enregistrer…?” qui s’ouvrent. Pas de choses inutiles installées dans votre navigateur, registre ou n’importe où dans votre système.
- Vie privée: DocFetcher ne collecte pas vos données privées. Jamais. Quiconque en douterait peut vérifier le code source qui est public.
- Gratuit/Libre pour toujours: comme DocFetcher est Open Source, vous n’avez pas besoin de vous inquiéter sur le fait que le programme devienne obsolète ou sans support, parce que le code source sera toujours disponible pour être utilisé. En parlant de support, savez vous que Google Desktop, un des compétiteurs commerciaux majeurs de DocFetcher’s a été arrêté en 2011? …
- Multi-plateforme: Contrairement à ses compétiteurs, DocFetcher ne fonctionne pas seulement sur Windows, mais aussi Linux et Mac OS X. Ainsi, si vous sentiez le besoin de laisser votre base Windows vers Linux ou Mac OS X, DocFetcher vous attendra de l’autre coté.
- Portable: Une des plus grandes forces de DocFetcher’s est sa portabilité. En fait, avec DocFetcher, vous pouvez construire une base de documents complète, qui peut être cherchée, et que vous pouvez emporter sur une clé USB.. Plus d’infos dans la section après.
- Indexez seulement ce dont vous avez besoin: Parmi les compétiteurs commerciaux de DocFetcher, il semble y avoir une tendance à inciter les utilisateurs à indexer le disque dur complet — peut être pour ne pas laisser à un utilisateur supposé “stupide” de choix, ou pire, pour collecter le plus de données utilisateur possible. En pratique, il parait raisonnable de penser que la plupart des gens ne veulent pas indexer leur disque complet: non seulement c’est une perte de temps et d’espace disque, mais aussi cela pollue les résultats de recherche avec des fichiers non désirés. Aussi, DocFetcher n’indexe que les dossiers que vous voulez explicitement être indexés, et en plus vous avez de nombreuses options de filtrage.
Base de documents portable
Une des fonctions remarquables de DocFetcher est qu’il est disponible dans une version qui vous permet de créer une base de documents portable — complètement indexée et cherchable de tous vos documents importants et que vous pouvez emporter avec vous.
Exemples d’utilisation: il y a des tas de choses que vous pouvez faire avec une telle base: vous pouvez l’emporter avec vous sur une clé USB, la graver sur un CD à dessein d’archivage, la mettre sur un volume crypté (recommandé: TrueCrypt, la synchroniser entre plusieurs ordinateurs via un service de stockage en ligne comme DropBox, etc. Mieux, comme DocFetcher est Open Source, vous pouvez même distribuer votre base: mettez en ligne et partagez là avec le monde entier si vous voulez.
Java: Performance et portabilité: Un des aspects qui pourrait ennuyer certains est le fait que DocFetcher a été écrit en Java, qui a la réputation d’être “lent”. Ceci était en fait vrai il y a dix ans, mais depuis les performances de Java se sont beaucoup améliorées, selon Wikipedia. De toute façon, le point positif sur le fait d’être écrit en Java est que le même package portable DocFetcher peut être exécuté sur Windows, Linux et Mac OS X — beaucoup d’autres programmes demandent des paquets séparés pour chaque plateforme. Il en résulte que vous pouvez, par exemple, mettre votre base sur une clé USB et y accéder de tous ces systèmes d’exploitation du moment que Java runtime y est installé.
Comment fonctionne l’indexation
Cette section essaye de donner un aperçu simplifié de ce qu’est l’indexation et de comment elle marche.
L’approche naïve pour la recherche de fichier: L’approche la plus basique pour la recherche de fichier est simplement regarder chaque fichier stocké un par un chaque fois qu’une recherche est effectué. Cela marche assez bien quand on recherche un nom de fichier seulement, car analyser les noms de fichiers est très rapide. Par contre, si vous vouliez chercher le contenu des fichiers, cela ne marcherait pas aussi bien car l’extraction du texte d’un fichier est bien plus coûteuse que la simple analyse de son nom.
Recherche basée sur un index: C’est pourquoi DocFetcher, qui permet de chercher le contenu, utilise une approche connue sous le nom d’indexation: l’idée de base est que la plupart des fichiers que les gens recherchent (typiquement plus de 95%) ne sont modifiés que très rarement ou pas du tout. Donc, plutôt que d’extraire le texte complet de chaque fichier à chaque recherche, il est beaucoup plus efficace de faire l’extraction une fois pour tous les fichiers, et de créer un index à partir de tout le texte collecté. Cet index est comme un dictionnaire qui permet rapidement de rechercher des fichiers à partir des mots qu’ils contiennent.
Analogie d’un annuaire: comme analogie, voyez comme il est plus efficace de trouver le numéro de téléphone de quelqu’un dans l’annuaire (l’“index”) plutôt que d’appeler chaque numéro possible juste pour voir si la personne de l’autre coté est celle que vous recherchez. — Appeler quelqu’un au téléphone et extraire le contenu texte d’un fichier peuvent tous deux être considérés comme des “opérations coûteuses” De plus, le fait que les gens ne changent pas souvent de numéro est similaire au fait que la plupart des fichiers sur un ordinateur ne sont que rarement modifiés.
Mise à jour de l’Index: Bien sûr, un index ne correspond à l’état des fichiers indexés que quand il a été crée, et ne prend pas forcément en compte les versions plus récentes des fichiers. Ainsi, si l’index n’est pas conservé à jour, vous pourriez obtenir des résultats de recherche périmés, de la même manière qu’un annuaire peut ne pas être à jour. Toutefois, ceci ne devrait pas être un gros problème si la plupart des fichiers ne changent que rarement. De plus, DocFetcher est capable de mettre à jour automatiquement ses index: (1) quand il est ouvert, il détecte les changements de fichiers et met à jour l’index de manière correspondante. (2) quand il n’est pas ouvert, un petit programme en tache de fond détecte les changements et garde une liste des index à mettre à jour; DocFetcher les mettra ensuite à jour au démarrage suivant. Et ne vous inquiétez pas au sujet du programme qui tourne en tâche de fond: il utilise très peu de ressources processeur et très peu de mémoire, dans la mesure où il ne fait rien à part noter quels dossiers ont été mis à jour, et laisse la mise à jour de l’index (qui est plus couteuse) à DocFetcher.
Syntaxe de la requête
Cette rubrique donne un aperçu de la syntaxe des requêtes disponibles, allant de “basic” à “advanced”. La syntaxe de la requête est fournie par Apache Lucene, le moteur de recherche sous-jacent de DocFetcher, et elle est décrite d’une manière plus technique sur la page syntaxe de la requête de Lucene.
Opérateurs booléens
DocFetcher supporte les opérateurs booléens OR, AND et NOT. Si les mots sont concaténés sans opérateurs booléens, DocFetcher les traitera par défaut comme s’ils étaient concaténés avec OR. Vous pouvez aller dans les préférences et définir ET comme valeur par défaut.
| Instead of OR, AND and NOT, you can also use | , && and ‘-‘ (minus symbol), respectively. You can use parentheses to group certain expressions. Here are some examples: | |
| Au lieu de OR, AND et NOT, vous pouvez également utiliser ** | , && et ‘-‘** (symbole moins), respectivement. Vous pouvez utiliser des parenthèses pour regrouper certaines expressions. En voici quelques exemples : |
| Requête | Les documents résultants contiennent… |
|---|---|
| chien OR chat | soit chien, soit chat, ou les deux |
| chien AND chat | à la fois chien et chat |
| chien chat | (par défaut équivalent à la requête chien OR chat) |
| chien NOT chat | chien, mais pas chat |
| -chien chat | chat, mais pas chien |
| (chien OR cat) AND mouse | mouse et (chien ou chat, ou les deux) |
Recherche NON sensible à la casse
DocFetcher ne fait pas la distinction entre les minuscules et les majuscules, donc peu importe si les mots que vous entrez sont complètement minuscules, ou complètement majuscules, ou un mélange des deux. Les seules exceptions sont les mots-clés OR, AND, NOT et TO, qui doivent toujours être entrés en majuscules.
Recherches de phrases et termes requis
Pour rechercher une phrase (c’est-à-dire une séquence de mots), mettez la phrase entre guillemets. Pour indiquer que les documents à rechercher doivent contenir un mot particulier, mettre un “ + “ devant le mot. Bien sûr, vous pouvez combiner ces constructions avec des opérateurs booléens et des parenthèses. Encore une fois, quelques exemples :
| Requête | Les documents résultants contiennent… |
|---|---|
| “chien chat souris” | les mots chien, chat et souris, dans cet ordre particulier |
| +chien chat | définitivement chien, et peut-être aussi chat |
| “chien chat” AND souris | l’expression chien chat, et le mot souris |
| +chien +chat | (équivalent à la requête chien ET chat) |
Caractères génériques (Wildcards)
Les points d’interrogation (’?’) et les astérisques (‘*‘) peuvent être utilisés pour indiquer que certains caractères sont inconnus. Le point d’interrogation représente exactement un caractère inconnu, tandis que l’astérisque représente zéro ou plus de caractères inconnus. Exemples :
| Requête | Les documents résultants contiennent… |
|---|---|
| luc? | lucy, luca, … |
| luc* | luc, lucy, luck, lucene, … |
| ene | lucene, energy, generator, … |
Remarque : Si des caractères génériques sont utilisés comme premier caractère d’un mot, la recherche a tendance à être plus lente en moyenne. Cela est dû à la structure de l’indice : C’est comme si vous essayiez de chercher le numéro de téléphone de quelqu’un, et vous ne connaissez que son prénom. Ainsi, dans l’exemple ci-dessus, la recherche de
*ene*sera probablement plus lente que les autres recherches car*ene*commence par un joker.
Recherches floues (Fuzzy Searches)
Les recherches floues vous permettent de rechercher des mots similaires à un mot donné. Par exemple, si vous recherchez roam~, DocFetcher trouvera des documents contenant des mots comme foam et roams.
De plus, vous pouvez ajouter un seuil de similarité entre 0 et 1, comme ceci : roam~0.8. Plus le seuil est élevé, plus la similarité des correspondances retournées est élevée. L’exclusion du seuil est identique à l’utilisation de la valeur par défaut de 0.5.
Recherches de proximité (Proximity Searches)
Les recherches de proximité vous permettent de trouver des mots qui se trouvent à une certaine distance l’un de l’autre. Pour effectuer une recherche de proximité, mettez un tilde (‘~’) à la fin d’une phrase, suivi d’une valeur de distance. - Notez que ceci est syntaxiquement similaire aux recherches floues. Par exemple, pour rechercher des documents contenant *wikipedia* et *lucene* dans un intervalle de 10 mots, tapez : "wikipedia lucene"~10
Stimuler les conditions (Boosting Terms)
Vous pouvez influencer le tri de pertinence des résultats en attribuant des pondérations personnalisées aux mots. Exemple : Si vous entrez chien^4 chat au lieu de chien chat, les documents contenant chien recevront un score plus élevé et se rapprocheront donc du haut des résultats.
Bien que le facteur d’amplification doit être positif, il peut être inférieur à 1 (par ex. 0,2). Si aucun facteur de suralimentation n’est spécifié, la valeur par défaut 1 est utilisée.
Recherches sur le terrain (Field Searches)
Par défaut, DocFetcher recherche dans toutes les données textuelles qu’il est capable d’extraire, c’est-à-dire le contenu, les noms de fichiers et les métadonnées des documents. Toutefois, vous pouvez également limiter vos recherches au nom du fichier et/ou à certains champs de métadonnées.
Par exemple, pour rechercher des documents dont les titres contiennent wikipedia, entrez : title:wikipedia.
La recherche de champ peut être combinée avec d’autres constructions de recherche, par exemple :
- Recherche d’expressions avec des guillemets, par ex.
titre : "chien chat", ou entre parenthèses, par ex.titre :(chien chat). Si vous omettez les guillemets et les parenthèses, seul le chien sera comparé au titre, pas le chat. - Caractères génériques :
title:dog*correspondra, par exemple, aux occurrences dedoggydans le titre.
Les zones disponibles dépendent généralement du format du document, mais vous pouvez les utiliser comme règle empirique :
- Fichiers : filename, title, author
- Courriels : subject, sender, recipients
Recherches par plages (Range Searches)
DocFetcher permet de rechercher des mots qui sont lexicographiquement entre deux autres mots. Par exemple, le mot bêta se situe entre alpha et gamma. Donc, si vous voulez lister tous les documents qui contiennent des mots entre alpha et gamma, tapez : [alpha TO gamma].
Lorsqu’on utilise les crochets, la requête de plage est inclusive, c.-à-d. que l’alpha et le gamma sont inclus dans les résultats. Pour faire une recherche exclusive, utilisez plutôt des crochets bouclés : {alpha TO gamma}
Vous pouvez combiner les recherches par plages et les recherches par champs comme suit : title:{alpha TO gamma}. Ceci limitera la recherche de plage au champ de titre.